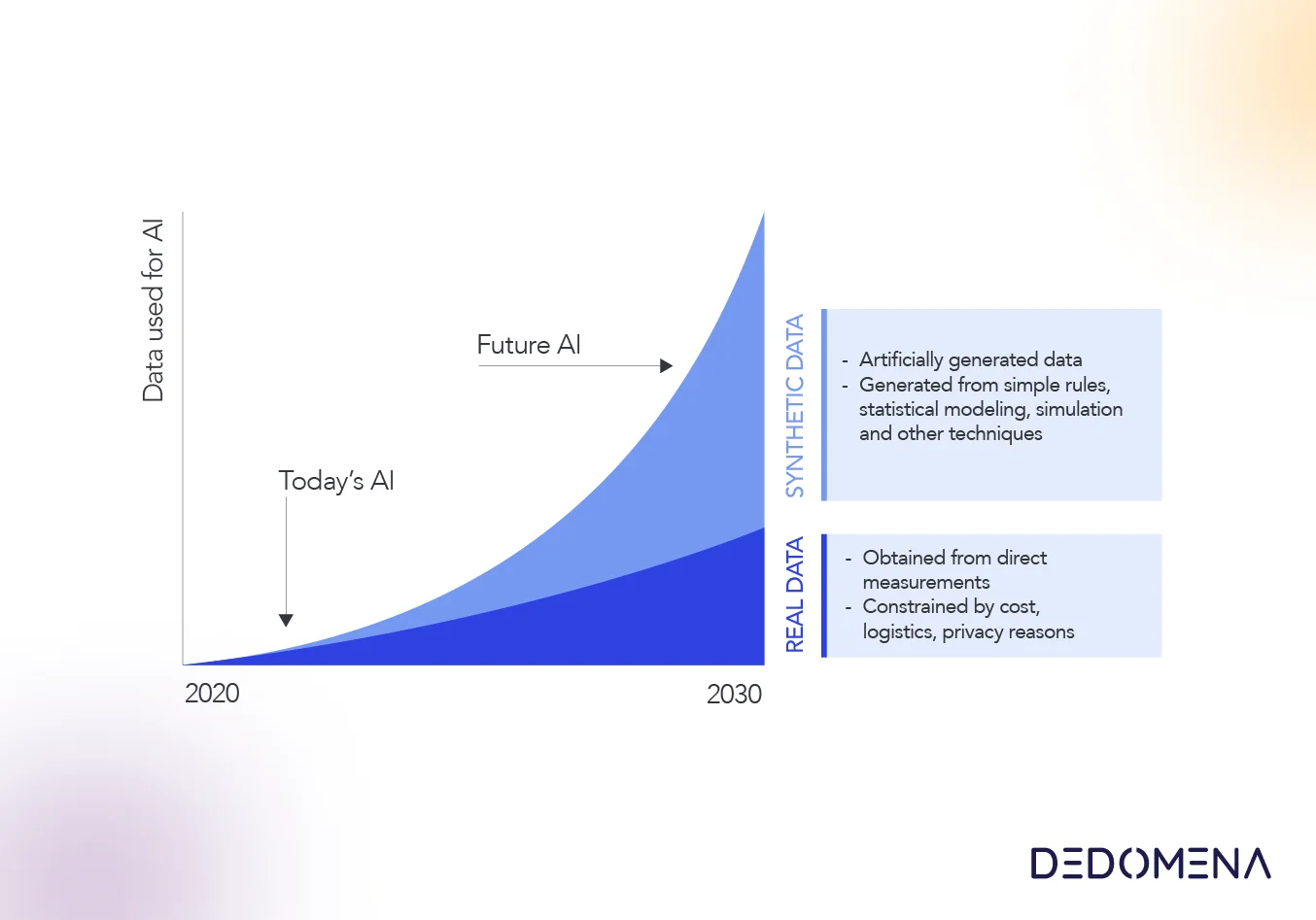
Imagine that you work at the Cardiology Department of the Central Hospital of Wakanda and you want to build a prediction model based on clinical data from your patients, in collaboration with the equivalent department of the Gregorio Marañon Hospital in Spain.
To collaborate with them, you need to share your patients dataset, but it has sensitive information. Therefore, you must anonymize the data while maintaining the original data utility, underlying patterns and probability distributions. Googling anonymization techniques, you realize that the best solution is to generate a synthetic dataset based on your original data, which, for the sake of understanding in this example, is the Stroke Prediction Dataset available on Kaggle.
So you have the following variables from the
5110 patients in your dataset:
- Gender: 59% Female, 41% Male.
- Age: from babies with months of birth to 82
years old patients.
- Hypertension: 1 if the patient is
hypertensive, 0 otherwise.
- Heart Disease: 1 if the patient has heart
disease, 0 otherwise.
- Ever Married: Has the patient ever been
married? 66% is True.
- Work Type: 5 options: Children, Never Worked,
Self Employed, Government Job, Private.
- Residence Type: Urban 51%, Rural 49%.
- Average glucose level: Average level of
glucose in the blood.
- BMI: Body Mass Index.
- Smoking Status: 4 options: Unknown, Formerly
Smoked, Smokes, Never Smoked.
- Stroke: Stroke event, 1 if yes, 0 otherwise.
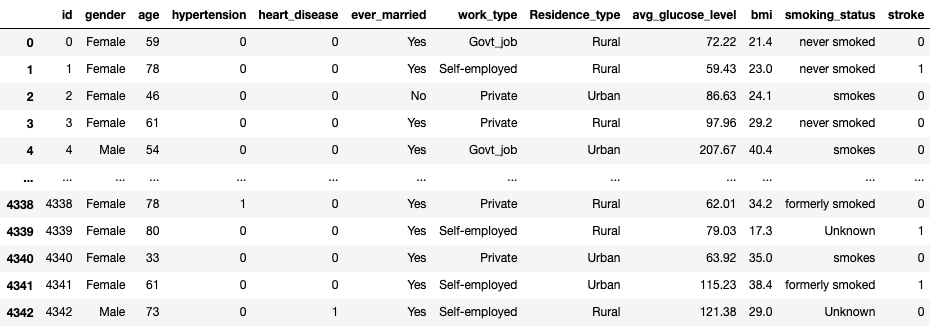
For each of the patients you have a unique id number. The data looks like this:
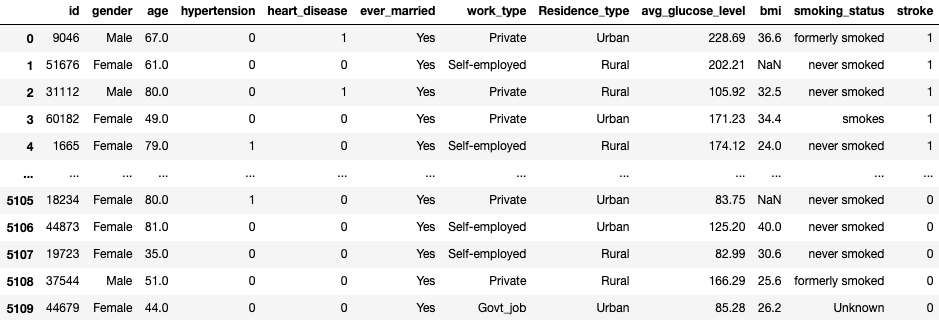
Since 4% of the BMI records are missing values, you imputed them based on the nearest neighbors using the KNNImputer class from scikit learn.
After that, you randomly split the original
dataset into two datasets:
1. Train dataset (85% of original records).
2. Test dataset (15% of original records).
To analyse the quality of the synthetic data, you are planning to build a machine learning model that classifies the patient into two categories: those who are highly likely to have a stroke or those who are not. To achieve this, you will train a Random Forest algorithm (no fine tuning, no cross validation, etc.) on the original dataset (Train) and the new synthetic dataset, making predictions with both resulting models on the same Test dataset and comparing the results.
Following this plan, you use our synthetic data
generation engine called Sinteza:
1. You enter the Train dataset.
2. Specify the primary key: Id.
When the process completes, you generate the same number of synthetic records: 4343.
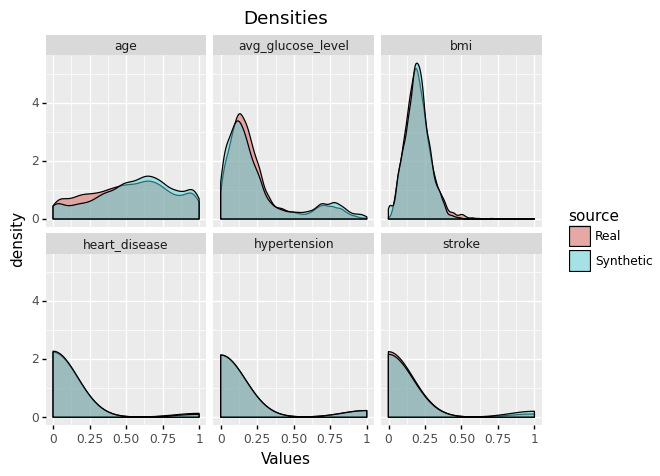
This allows you to compare the original Train dataset and the synthetic dataset through the metrics we provide.
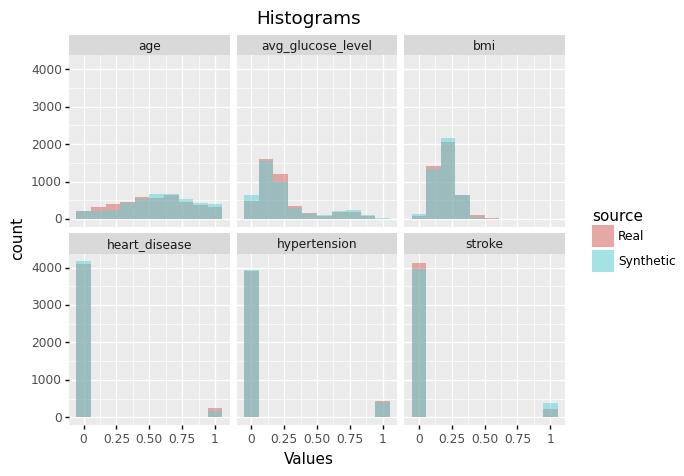
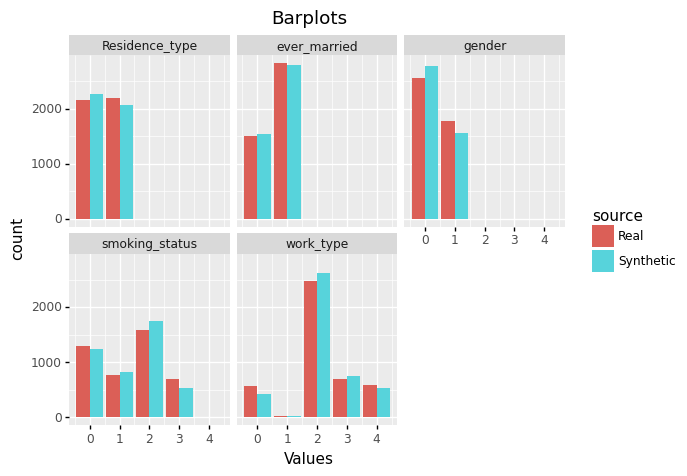
Metrics
Below you can find the results for some of the metrics we compute in our quality report. They show how good the synthetic data is compared to the original.
Distance to Closest Record
Original Dataset:
0.25: 2.186687 0.5: 2.725821 0.75 3.476650 Avg:
2.796386
Synthetic Dataset:
0.25: 2.156844 0.5: 2.753047 0.75 3.451898 Avg:
2.787263
Nearest Neighbor Distance Ratio
Original Dataset:
0.25: 0.752828 0.50: 0.863203 0.75: 0.938945
Synthetic Dataset:
0.25: 0.753449 0.50: 0.866232 0.75: 0.940377
Identical Match Share - Original vs Synthetic
Data
(We compare with all the original records
available before the Train / Test split)
IMS: 0.0%. 0 out of 5110 have identical matches
within the original data.
Correlation Matrix (Top: Original - Bottom:
Synthetic)
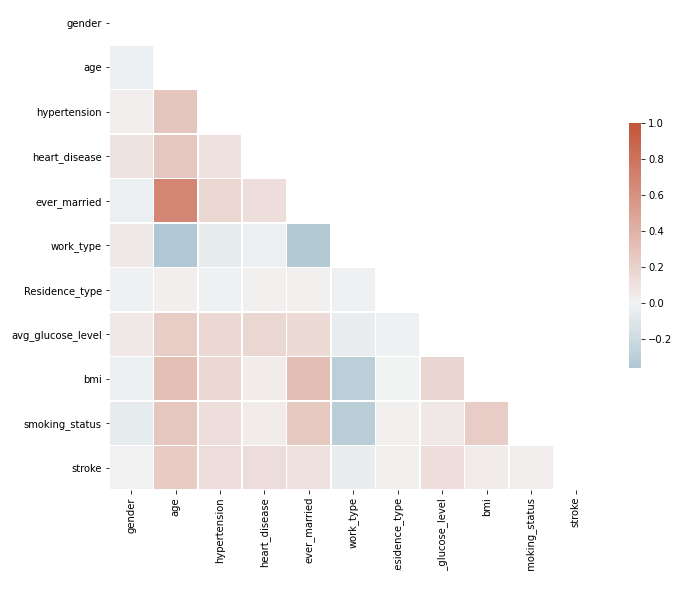
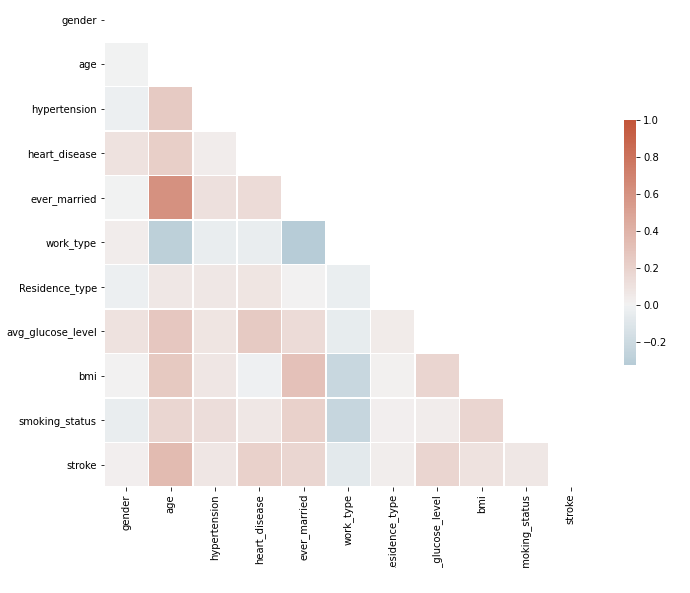
To conclude, you create two models, training the
same Random Forest algorithm with the same
hyperparameters on both datasets:
1. The original Train dataset.
2. The synthetic dataset (with the same number
of rows as the original).
Creating synthetic data using SINTEZA is the best way to anonymize your dataset.
To improve the performance of the models and because that might be a natural step before training if you are working with the original dataset, you previously oversampled the minority class of the target variable (Stroke) with a SMOTE algorithm. You do it on both datasets to have the same pipeline of data transformations that lead to more reliable results in terms of comparison.
Then you make predictions on the Test dataset
using both models. The results are the
following:
Accuracy of the model trained with original
data: 0.8657
Accuracy of the model trained with synthetic
data: 0.8579
F1 Score of the model trained with original
data: 0.1889
F1 Score of the model trained with synthetic
data: 0.1550
ROC AUC Score of the model trained with original
data: 0.5486
ROC AUC Score of the model trained with
synthetic data: 0.5339
Conclusions
As you can see, the synthetic data generated keeps the patterns and statistical info of the original dataset, but being synthetic, it ensures patient privacy. Creating synthetic data using SINTEZA is the best way to anonymize your dataset. Now you can share the synthetic dataset with the Cardiology Department of the Gregorio Marañon Hospital. Well done!